Most security teams are underwater. The industry tells them to shift left — find and fix problems before they ship — but that assumes capacity that most simply don't have. Meanwhile, AI is lowering the cost of finding and exploiting vulnerabilities, which means incidents arrive faster and more frequently.
The reality is most teams are already operating to the right of where they want to be. Rather than treating reactive work as a failure mode, we can view shift-right as the best opportunity to make structural improvements. This is because incident response is one of the few moments when meaningful hardening work can actually get done: the urgency is real and resources become available.
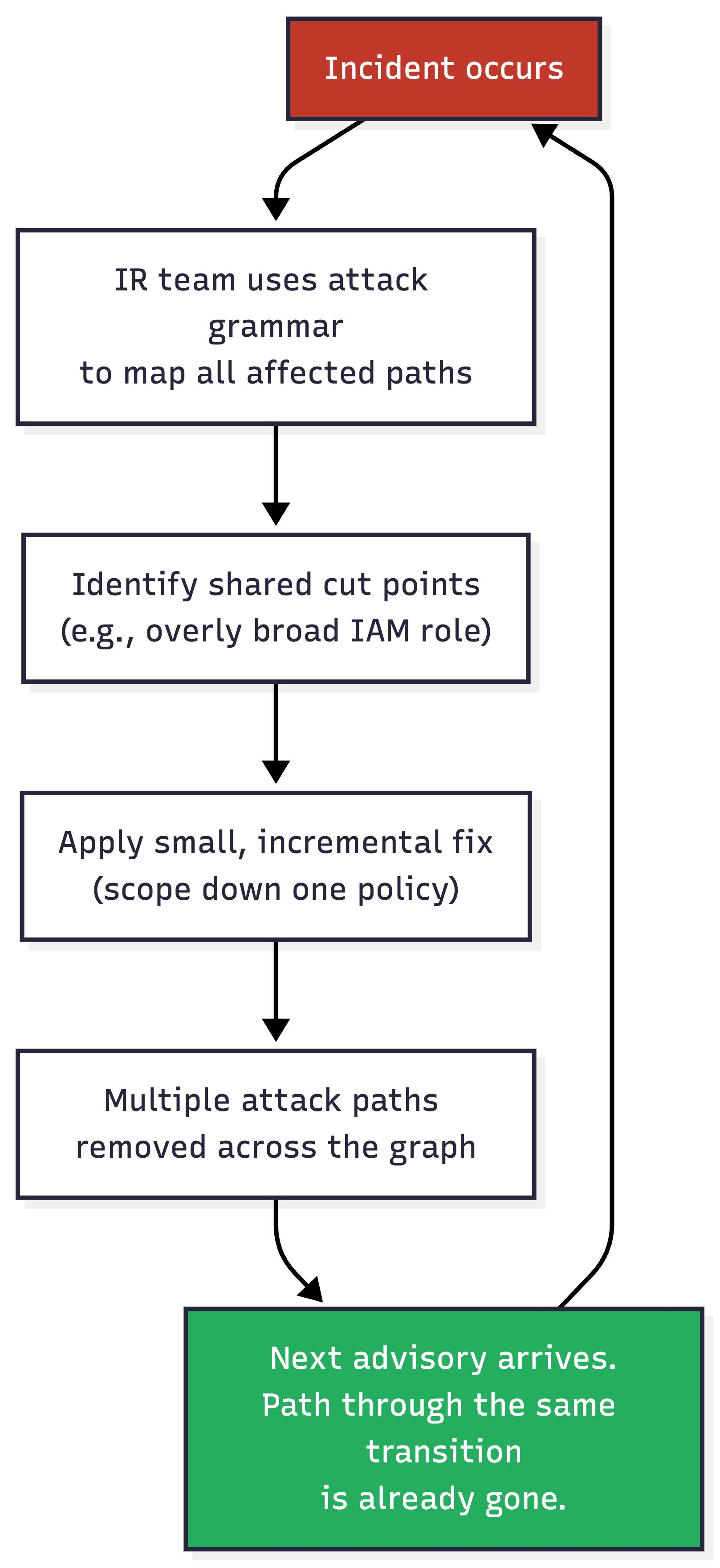
This blog shows how attack path analysis can drive continual improvement of a security program, forming a flywheel where each incident leaves fewer attack paths than the last.
We recently shipped attack path analysis in SubImage and pointed it at our own infrastructure first. The results were more interesting than we expected.
The Trivy -> LiteLLM supply chain incident in March 2026 is a useful reference point. The important part was not just that a malicious Trivy version existed; it was that Trivy ran inside LiteLLM's CI pipeline with access to their PyPI publishing credentials. A compromised scanner reached a publishing control plane, and from there a heavily used package was poisoned.
We put something similar together with our own infra at SubImage:
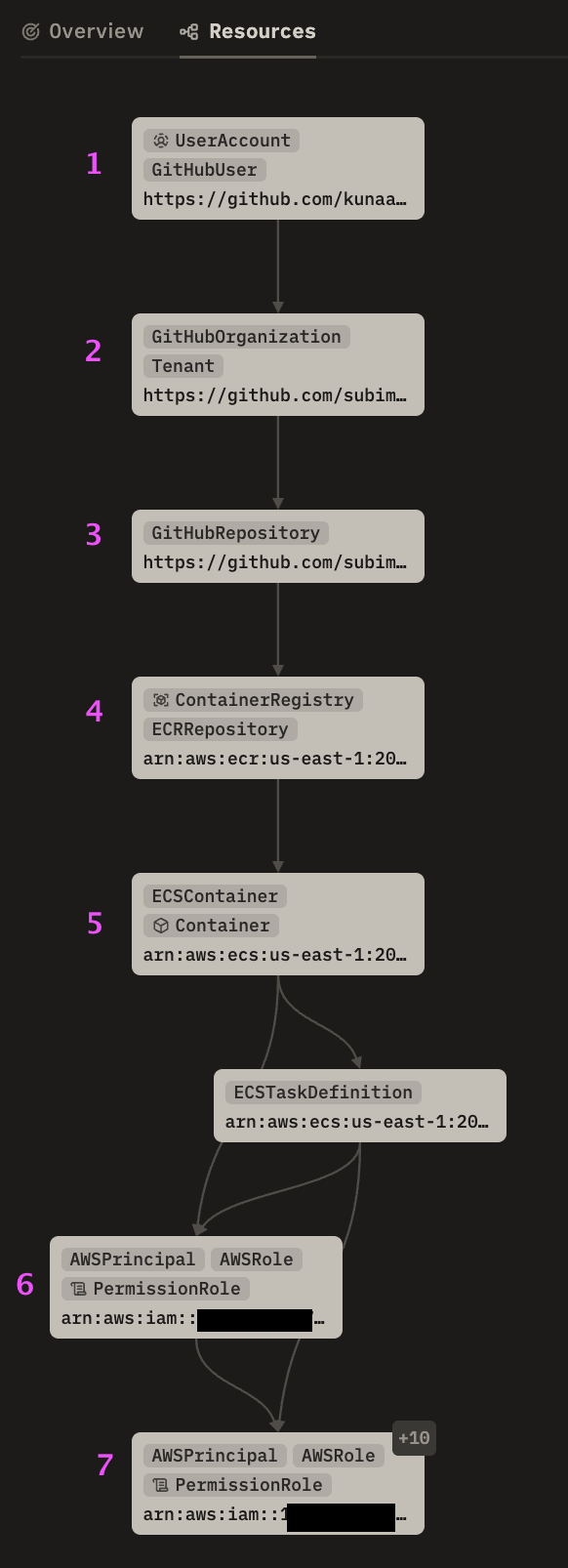
There is nothing especially exotic in any individual hop:
The engine also found another supply chain related attack path from the same monorepo but through a different container image:
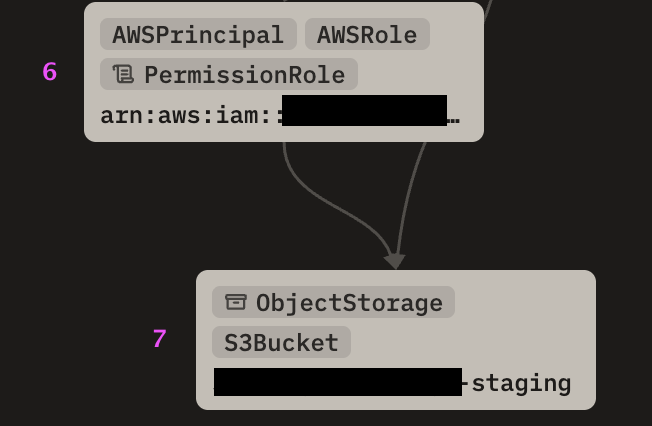
Both paths run through step 6 — that's where code execution picks up an IAM role via the task definition. Before step 6, the attacker has code execution in a container. After step 6, they have AWS credentials.
We see two areas for improvement:
Fix 1: Scope down one task role's sts:AssumeRole policy and the cross-account path breaks.
Fix 2: Tighten the other role's S3 permissions and the exfiltration path breaks.
These are small, incremental changes that likely won’t cause controversy when presented to the rest of the engineering org, but add up over time.
When we scope down a task role's AssumeRole policy during incident response, we're removing a transition that appears in paths across the entire graph. The fix is small, but its effect is combinatorial.
Suppose that three weeks later, a different supply chain advisory comes out, and the path from the newly compromised component to our downstream accounts is gone thanks to our prior remediation efforts. This has prevented another fire drill not because we ran a proactive hardening sprint (who has time for that), but because the last incident response pointed us at the right boundary.
Neither path came from a hard-coded rule that checks for "GitHub org admin -> ECR -> ECS -> cross-account AssumeRole."
Most cloud security tools offer some version of attack path analysis today. The difference is in how paths are constructed. Rule-based engines work by enumerating known-bad patterns: if A connects to B connects to C, then flag it. Coverage is bounded by what someone thought to write a rule for.
That approach finds known patterns well, but it doesn't naturally support the kind of incident-driven improvement we're describing; when you fix a transition during IR, a rule-based engine can't tell you what other paths that fix just eliminated.
Instead, our engine uses what we call an attack grammar, which is a set of general-purpose transition types that describe how an attacker moves through infrastructure.
initial_compromise → root_access →
supply_chain → iam_usage → privilege_escalation
Each transition describes a type of move: source control to build system, build system to container, container to IAM role, IAM role to data store, etc.
A finite vocabulary of transition types composes into an open-ended set of paths. When infrastructure changes — a new service, a new role, a new trust relationship — the engine explores compositions through it on the next sync without anyone writing a new rule. Coverage scales with the infrastructure, not with one's capability to author detections.
In practice, we specify nodes of interest to simulate what-if-this-was-compromised scenarios, and when the paths change, we know something in the environment shifted.
Security teams don’t need another tool that finds problems they cannot get to; rather, they need each piece of forced work to do more than one job.
When incident response is informed by a graph of reusable attacker transitions, the fix we make for today’s incident can remove paths for incidents that have not happened yet. This is the shift-right flywheel where each response leaves fewer attack paths than the one before it.
Attackers think in graphs, defenders should too, and the highest leverage moment to act on that is right in the middle of the fire drill you’re already running.