This past Wednesday I had the chance to use our own product to fix the React2Shell vulnerability on SubImage's infrastructure (P.S. If you're concerned about this vuln, this guidance from Vercel is a good resource).
I love learning from incidents like this because they quickly expose whether what we're building is useful or Yet Another Single Pane of Glass™️ that helps no one. Within minutes we knew we had the vulnerable package, which workloads were affected, whether it was exploitable, and we shipped a fix anyway.
This post is me bragging a little about our product and our deployment stack :), but it's also a walkthrough of what worked, what we want to improve, and some broader reflections on modern vulnerability management.
We saw the news of the vuln on Wednesday and conveniently enough, it showed up as a critical result on the SubImage deployment that we use for ourselves.
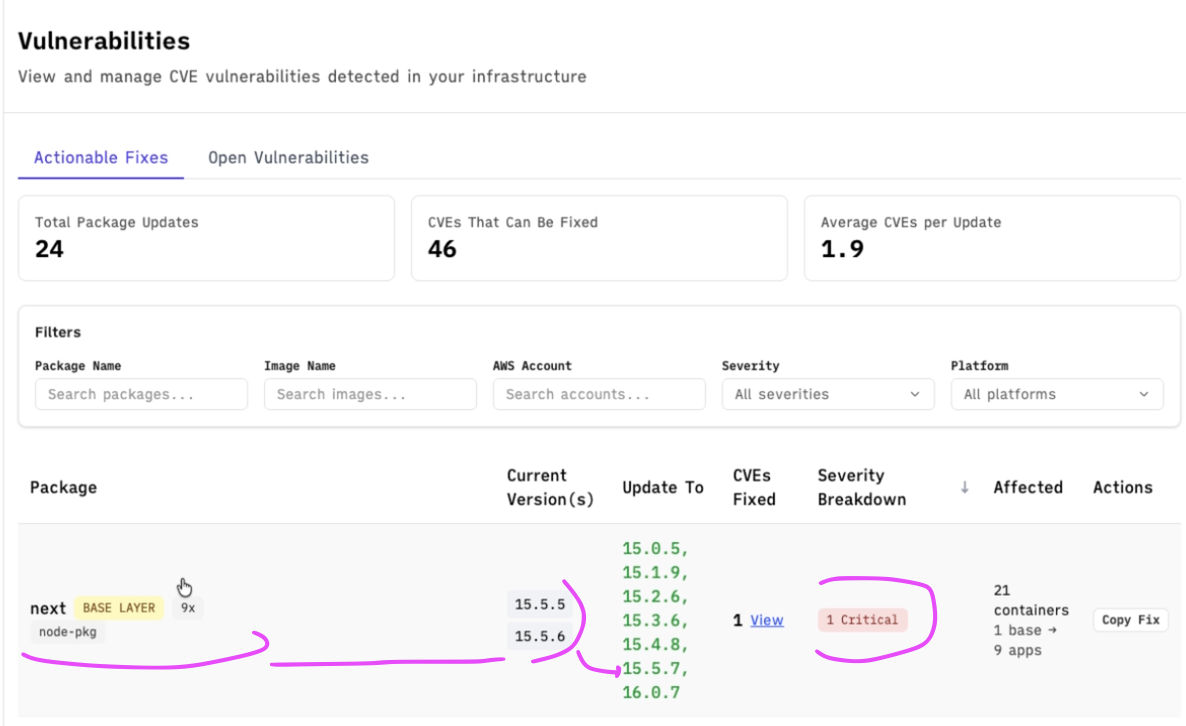
I was able to drill down and find out that React2Shell was affecting us on our backend, frontend, and scanner services on AWS ECS:

Our frontend does run next.js so it makes sense that the vulnerable version would be present there, so it was a bit surprising that it was also present on the backend and scanner.
This is an opportunity for improvement:
use server directive, so if our code doesn't use that, then we're not affected.As a side note, we also run a Kubernetes cluster for testing (not for prod; that'd be severe overengineering at our stage :x)
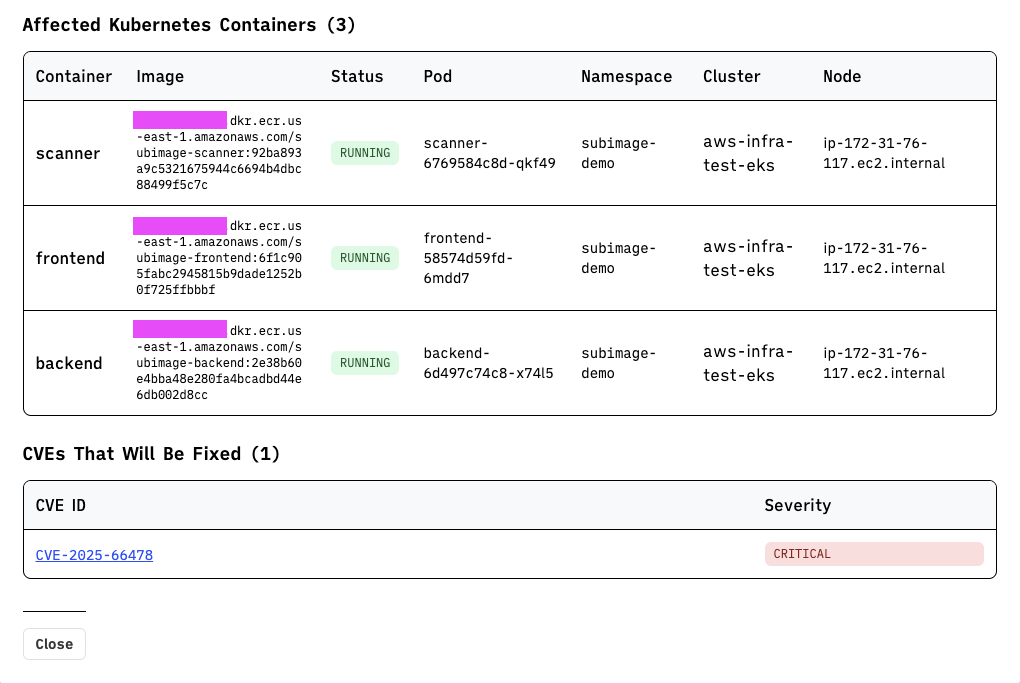
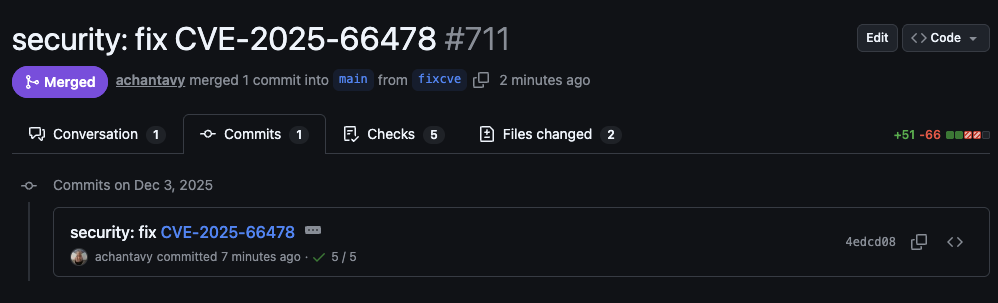
Regardless of exploitability, the fix was straightforward, so we just got it done. We prepared the fix:

merged it to main:
and then deployed it to staging to make sure it didn't break anything in prod:
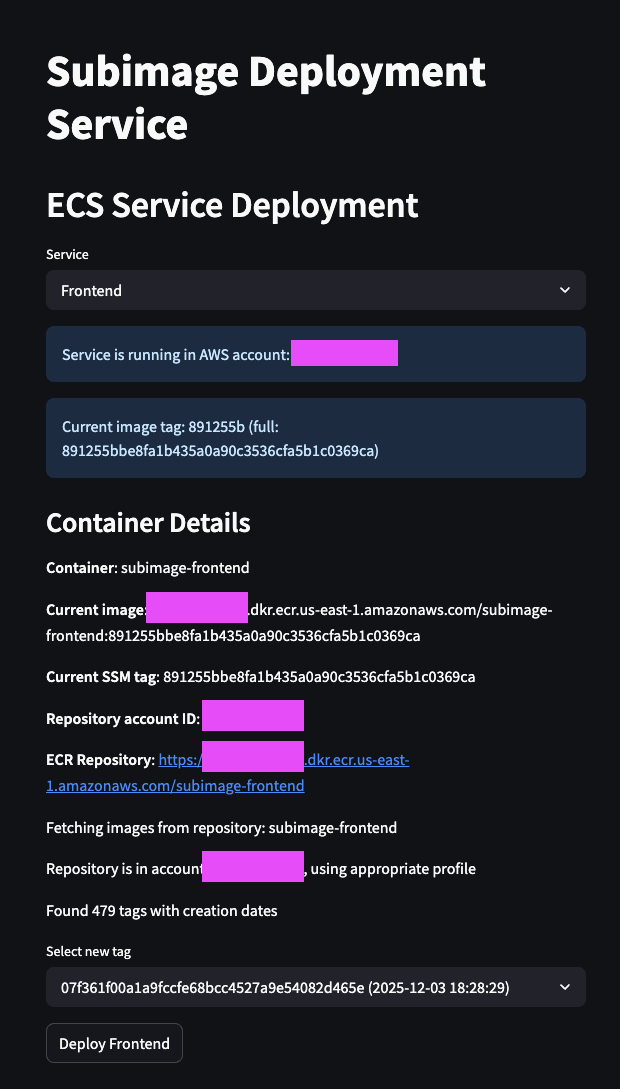
As another side note, this deploy setup is heavily inspired by our time at Lyft and their world class dev tooling.
SubDeploy goes ahead and triggers a change in ECS:
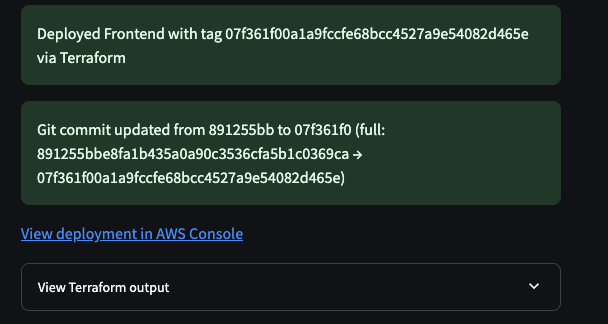
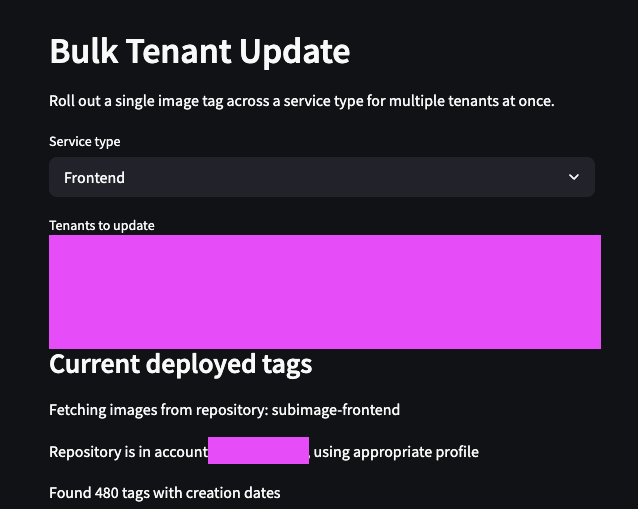
We verified that everything worked in staging, and then rolled out the change to all of our tenant environments:
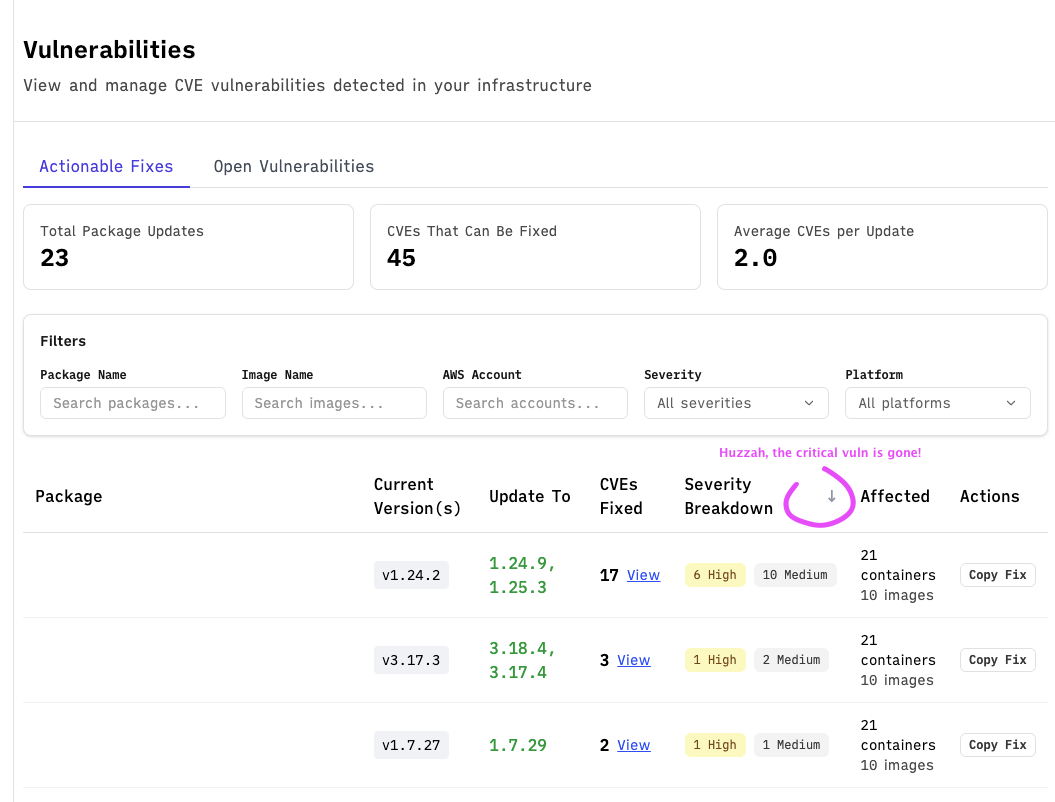
Our vuln scan ran an hour later, and confirmed that we had resolved the issue🎉. End to end, it took longer for our container image to build than for me to understand what was going on and get a fix shipped.
I'm proud that we were able to build something that helped our own security, especially because having the problem yourself is the best source of product discovery for a startup.
Let's zoom out for a moment. The React2Shell vuln allows an attacker to craft a payload that grants them arbitrary remote code execution on a machine running a vulnerable version of next.js if React Server Actions are enabled. Going through the vuln mgmt triage process...
Yes.
Yes, this was the initial alert.
No, we do not use React Server Actions on any of our frontend components.
Theoretically yes. SubImage (via Cartography) integrates with SAST tools like Semgrep, and it's possible to enrich SubImage's vuln data with that context.
At this point we're done with our investigation because we didn't even use the affected feature, but for the sake of argument let's pretend that we did. Here are some questions we should ask next. I'll group them into protect, detect, and respond categories.
If React2Shell led to RCE on our Next.js server, the attacker would inherit the frontend server’s own permissions. The frontend already talks to the backend using authenticated APIs, so an attacker with server-level access could call those same APIs and retrieve or modify any data the frontend is authorized to access.
SubImage maps out what IAM roles are used by the frontend and backend, so we are able to see the full potential blast radius.
With SubImage we know what libraries are present on our systems through both container image scans and GitHub dependency manifests. Detecting if the relevant features are enabled and reachable is trickier, but Cartography integrates with SAST tools like Semgrep to help answer this question.
A runtime sensor would help here, though depending on the application this may be too invasive. It's also possible to configure cloud provider specific alerts for this kind of thing.
In our case, it was as simple as cutting a PR and then using SubDeploy to ship the fix to all tenants. ezpz.
Modern vulnerability management needs more than answering "is CVE-123 present?". It requires context, like:
In this specific case, our fix action was very simple (cut PR + deploy) so it was better to eliminate the potential attack path as quickly as possible, even if we may not be affected.
More broadly, both fast patching and fast understanding are a must. SubImage helped us answer most of those questions within minutes, and I'm excited to sharpen the whole experience over time.